Fala pessoal, tudo bem?
Já falei algumas vezes por aqui sobre otimização, mas nunca sobre como SQL Server executa uma query. Hoje vou falar sobre a ordem de execução de uma query, como ela pode te ajudar a escrever consultas com melhor desempenho e passar algumas dicas.
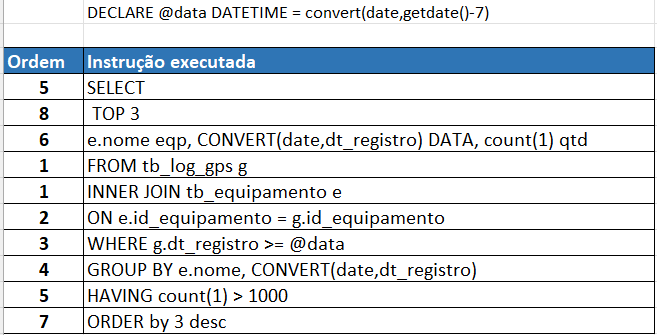
Vamos supor que tenhamos a consulta. Essa consulta busca os 3 equipamentos (TOP 3) ordenado pelo maior número de eventos (order by desc) que tiverem mais de 1000 registros por dia (group by e having) de GPS enviados nos últimos 7 dias (where).
DECLARE @data DATETIME = convert(date,getdate()-7)
SELECT TOP 3 e.nome eqp, CONVERT(date,dt_registro) DATA, count(1) qtd
FROM tb_log_gps g
INNER JOIN tb_equipamento e ON e.id_equipamento = g.id_equipamento
WHERE g.dt_registro >= @data
GROUP BY e.nome, CONVERT(date,dt_registro)
HAVING count(1) > 1000
ORDER by 3 desc
OPTION(RECOMPILE)As consultas SQL são executadas na seguinte ordem:
- FROM/JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP/OFFSET
Conhecendo como o SQL obtem os dados podemos ter a oportunidade de tornar cada query mais eficiente.
Com isso em mente, podemos tomar algumas abordagens para ajudar o query optimizar a buscar dados de uma forma mais eficiente.
1 ) Se possível, filtrar dados antes do join através de subqueries e logicamente tomar o cuidado de escrever o join corretamente para evitar o produto cartesiano.
Por exemplo, na tabela podem existir registros de gps deletados logicamente que não devem fazer parte do resultado ou na tabela de equipamento existir equipamentos inativos que não devem fazer parte do resultado.
Poderíamos escrever e testar como seria o comportamente substituindo a tabela por uma query buscando somente as colunas que serão utilizadas na query principal e filtrando os equipamentos ativos:
DECLARE @data DATETIME = convert(date,getdate()-7)
SELECT TOP 3 e.nome eqp, CONVERT(date,dt_registro) DATA, count(1) qtd
FROM tb_log_gps g
INNER JOIN (select id_equipamento, nome from tb_equipamento where status = 'Ativo') e ON e.id_equipamento = g.id_equipamento
WHERE g.dt_registro >= @data
GROUP BY e.nome, CONVERT(date,dt_registro)
HAVING count(1) > 1000
ORDER by 3 desc
OPTION(RECOMPILE)Como não existe uma receita que funcionará para todos os ambientes, tudo precisa ser testado, pois irá variar de acordo com a indexação das tabelas, fragmentação, atualização das estatísticas, versão e configuração do sql, volume e cardinalidade de dados e a eficiência do índice, etc..
2 ) Na segunda etapa e uma das mais importantes, sempre que possível criar filtros bem seletivos, com isso seu result set será bem menor fazendo com que o SQL reserva com base em estimativas menos recursos e durante a execução utilize menos recursos.
3) Vejo muita gente utilizando group by no lugar do disctinct e funciona para vários cenários na obtenção dos dados, mas como dito anteriormente não há uma receita que funcionará com melhor desempenho em qualquer ambiente.
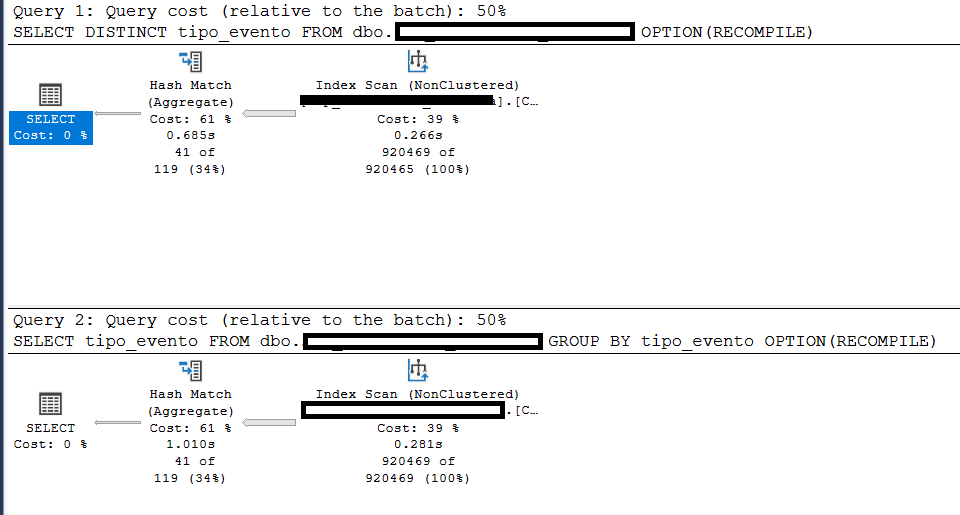
Veja esse exemplo, executei quatro vezes as mesmas duas consultas. A tabela tem cerca de 1 Milhão de registros fazendo um disctint em uma coluna na primeira query e o group by pela mesma coluna do distinct.
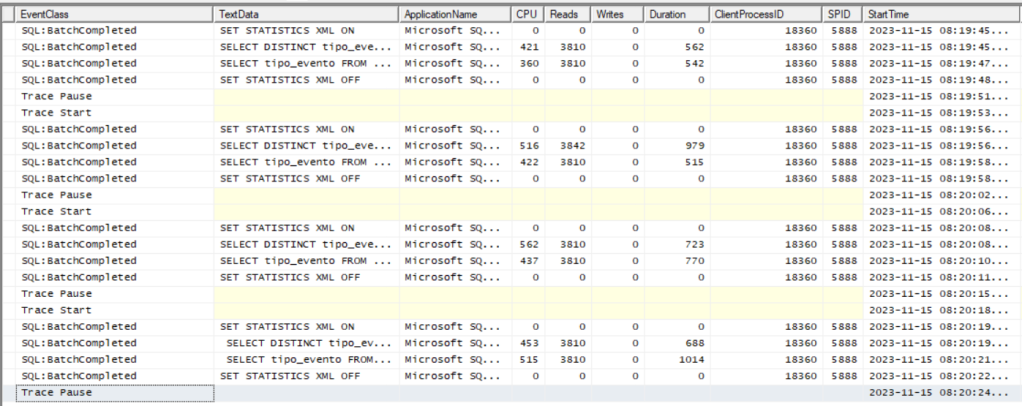
Segue o plano de execução são iguais assim como as leituras de páginas exibidas anteriormente. Nas duas primeiras execuções, o select com disctinct foi mais rápido e nas duas últimas o select com group by, foi mais rápido. Já vi posts na internet que cravam que o select com distinct sempre será mais rápido ou igual ao grupo. Eu não tenho coragem de afirmar isso! 🙂
4) Se possível, traga os filtros que vc pensou em utilizar na cláusula having para o Where, reduzindo assim seu result set antes de todo o processo de agrupamento e filtragem do having.
5) Sempre que houver uma agregação junto com a cláusula top, todo o result set será processado e depois a cláusula top terá um pequeno custo no total da execução da query. Porém caso não haja a agregação, a utilização do top pode te ajudar bastante na obtenção de dados, tente utilizar o TOP 100 pois o SQL Server tem um comportamente diferente na cláusula top até o valor 100, para os valores acima. Isso provavelmente será tópico de outro post.
Algumas outras dicas gerais rápidas para melhorar o desempenho das suas consultas:
6) Certifique-se que os índices corretos estejam criados.
7) Cuidado com a conversão implícita, que é basicamento utilizar parâmetros ou campos em joins ou filtros com tipos de dados diferentes das colunas filtradas.
8) Limite as colunas da query ao invés de utilizar *, normalmente o * fará o query optimizer efeturar o lookup ou um scan na tabela.
9) Cuidado ao filtrar string onde seu parâmetro inicia com %.
10) Cuidado ao utilizar collation do Windows ao invés da collation do SQL Server.
11) Sempre que possível utilizar union all ao union.
O tópico do post era explicar a ordem de execução da query e com base nisso acabamos passando algumas dicas para você escrever boas consultas.
Por hoje é isso e caso tenha alguma outra dica, não deixe de citar aqui nos comentários.
Abraços
