Fala pessoal, tudo bem?
Depois que escrevi sobre a diferença de FK e índice nesse post aqui tive algumas outras ideias para exemplificar sobre outros problemas que vemos no dia a dia.
Para resumir, temos uma tabela de 10 linhas e ao tentar apagar um registro estava demorando uma eternidade. O que podemos avaliar inicialmente caso não ocorra um erro logo de cara.
- Ocorre algum bloqueio ao realizar a operação?
- Existe trigger na tabela?
- Existe relacionamentos na tabela?
- Se existir relacionamentos, as colunas relacionais estão devidamente indexadas?
Para simular esse cenário executei o script:
-- Cria tabelas
CREATE table categoria (id int identity(1,1) PRIMARY key, descricao varchar(1000))
Create table produto (id int identity(1,1) PRIMARY key, descricao varchar(1000), id_categoria int)
-- Cria relacionamento
ALTER TABLE produto
ADD FOREIGN KEY (id_categoria) REFERENCES categoria (id);
GO
-- insere dados na tabela categoria
INSERT INTO dbo.categoria
(
descricao
)
VALUES
('brinquedo' ),
('comida' ),
('automóvel' ),
('pc' ),
('calçado' ),
('Roupas' )
GO
-- SELECT * FROM categoria
-- insere dados na tabela produto
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 120000 c.name , 1 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 230000 c.name , 3 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 230000 c.name , 3 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 230000 c.name , 3 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 430000 c.name , 4 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 400000 c.name , 4 from sys.tables t cross join syscolumns c
GO
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 400000 c.name , 4 from sys.tables t cross join syscolumns c
GO 10
INSERT INTO dbo.produto
(
descricao,
id_categoria
)
select top 120000 c.name , 6 from sys.tables t cross join syscolumns c
GO
-- verifica tamanho da tabela
EXEC sp_spaceused categoria
GO
EXEC sp_spaceused produto
GO

No nosso caso, é devido a falta de índice em um foreign key, mas para avaliar se existem bloqueios você pode utilizar a procedure sp_whoisactive ou utilizar o script que disponibilizei nesse post.
Para validar se existe trigger na tabela que vc está tentando executar o delete você pode usar a consulta abaixo, ou navegar no object explorer do ssms, até encontrar a tabela expandir as propriedades e abrir a pasta “Triggers”.
SELECT * FROM sys.triggers WHERE OBJECT_NAME(parent_id) = 'categoria'
Após gerar a massa de dados, tentei executar o delete em uma categoria que não tinha dados relacionados na outra tabela.

Por causa do relacionamento explícito através da FK, durante a operação de delete o engine do SQL precisa garantir que não existem dados na tabela produto com o id da categoria a ser excluído, por isso o alto volume de logical reads e a alta duração para excluir apenas uma linha.

Após criar o índice para cobrir a fk com o script abaixo, a operação de deleção ficou mais rápida, passando a ler apena 3 páginas da tabela produto e a duração de 0 milisec.
CREATE INDEX Ix_produto_id_categoria ON produto (id_categoria)
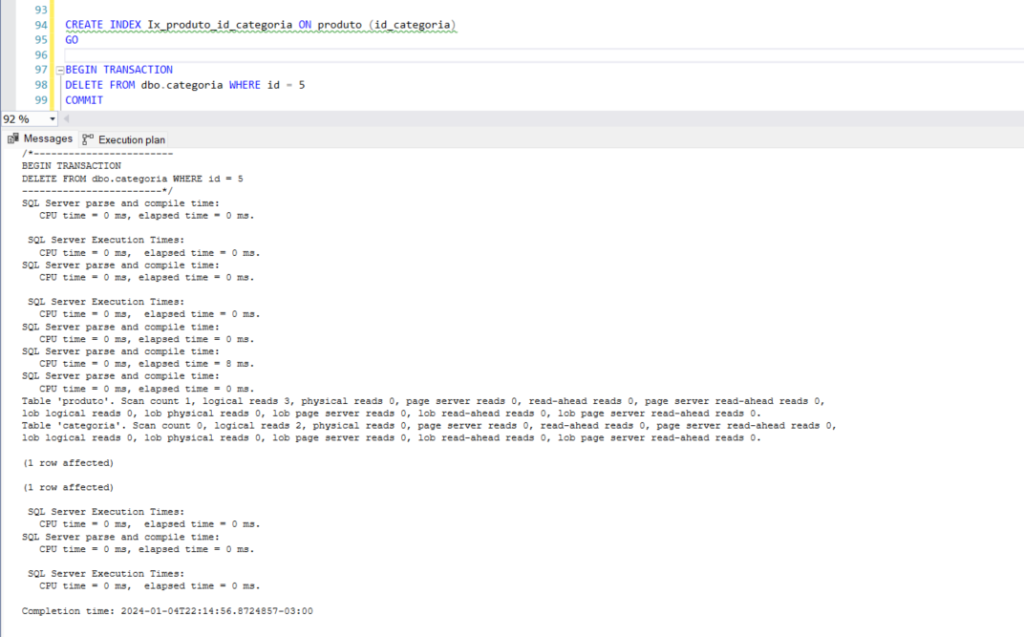

Como na declaração de criação da constraint não incluímos a especificação de cascade, um erro será gerado devido a integridade dos dados.
Para fazer o delete eu identifiquei quantas linhas haviam em cada categoria.

Em seguida efetuei o delete na id categoria 5.
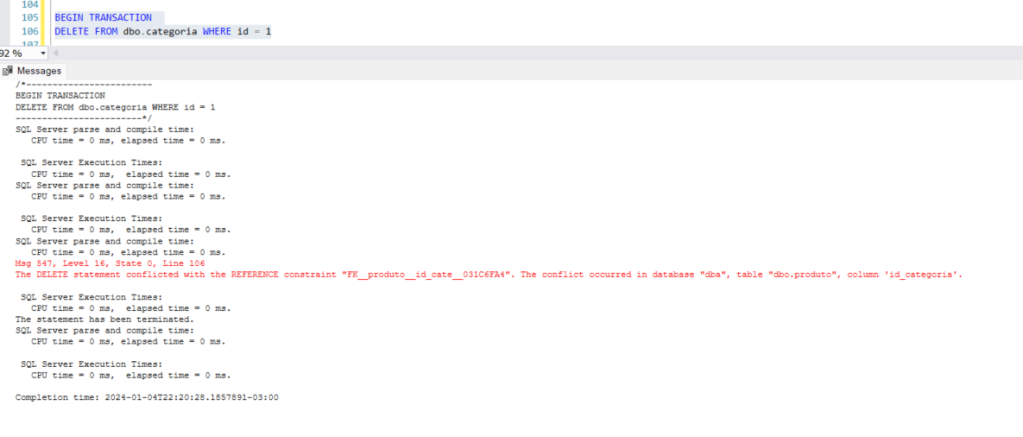
Tivemos o erro:
Msg 547, Level 16, State 0, Line 106
The DELETE statement conflicted with the REFERENCE constraint “FK__produto__id_cate__031C6FA4”. The conflict occurred in database “dba”, table “dbo.produto”, column ‘id_categoria’.
Para que o erro não ocorra podemos implementar na “aplicação” ou via trigger uma lógica para apagar os registros da tabela produto que depende do relacionamento com a tabela categoria, ou alterar a especificação da FK incluindo a propriedade cascade.
Temos duas opções para o cascade e são elas.
DELETE CASCADE : Quando criamos uma chave estrangeira usando esta opção, ela exclui as linhas de referência na tabela filho quando a linha referenciada é excluída na tabela pai que possui uma chave primária.
UPDATE CASCADE: Quando criamos uma chave estrangeira usando UPDATE CASCADE, as linhas de referência são atualizadas na tabela filha quando a linha referenciada é atualizada na tabela pai que possui uma chave primária.
Conseguimos criar uma nova fk entre as tabelas, porém o ideal é apagar a já existente e criar a nova para garantir as regras de exclusão e podemos utilizar no nosso exemplo os scripts abaixo:
-- drop a constraint anterior sem cascade
ALTER TABLE produto DROP CONSTRAINT FK__produto__id_cate__031C6FA4
GO
-- Cria relacionamento com delete cascade
ALTER TABLE produto
ADD FOREIGN KEY (id_categoria) REFERENCES categoria (id)
ON DELETE CASCADE
GO
EXEC sp_help produto
GO

Agora que temos a constraint configurada com o delete cascade, vamos novamente tentar fazer o delete.
Tivemos um alto volume de leitura de páginas e pelo plano de execução podemos observar que foi realizado o spill para o tempdb devido as 120000
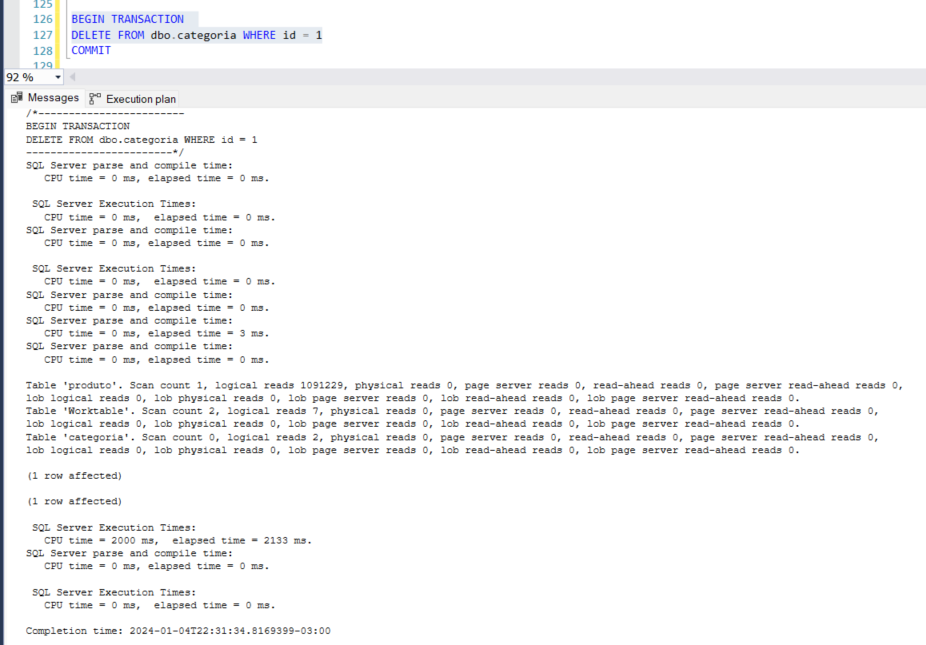

E então, depois de alterar a fk com a opção delete cascade, foi realizada a exclusão do registro da tabela categoria e os 120 mil registros da tabela produto, em um tempo aceitável de aproximadamente 2 segundos, pois estava com o índice criado.
Por hoje é isso pessoal.
Abs
