Fala pessoal, tudo bem?
Estamos sempre avaliando vários ambientes diferentes porém vemos “quase” sempre os mesmo problemas, e um muito comum são tabelas que possuem relacionamentos (FK) sem índices.
No SQL Server, a Foreign Key (FK) e o “índice” são conceitos distintos, mas ambos desempenham papéis importantes em garantir a integridade dos dados e otimizar o desempenho das consultas.
- Chave Estrangeira (FK – Foreign Key):
- A chave estrangeira é um conceito usado para estabelecer uma relação entre duas tabelas.Uma chave estrangeira em uma tabela faz referência a uma chave primária ou única em outra tabela.Ela é usada para manter a integridade referencial, o que significa que não pode haver valores na chave estrangeira que não correspondam a valores na chave primária ou única da tabela referenciada.A principal finalidade da chave estrangeira é garantir a consistência dos dados entre tabelas relacionadas.
- Índice:
- Um índice é uma estrutura de dados que melhora a velocidade de recuperação de linhas de uma tabela com base nos valores de uma ou mais colunas.
- Os índices ajudam a otimizar o desempenho das consultas, permitindo que o banco de dados localize registros mais rapidamente.
- Enquanto as chaves primárias e estrangeiras normalmente têm índices associados automaticamente, é possível criar índices adicionais para otimizar consultas específicas.
Para exemplificar criei duas tabelas, populei com dados e vamos fazer uma query simples consultando a quantidade de um erro específico.
CREATE TABLE [dbo].[Dga_Erro](
[id_erro] [INT] IDENTITY(1,1) NOT NULL,
[col1] VARCHAR(100)
CONSTRAINT [pk_dga_Erro] PRIMARY KEY CLUSTERED
(
[id_erro] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DGA_log_error](
[id_cb_log_erro] [bigint] IDENTITY(1,1) NOT NULL,
[id_erro] [int] NULL,
[log] [varchar](max) NOT NULL,
[android_versao] [varchar](50) NOT NULL,
[tablet_modelo] [varchar](50) NOT NULL,
[dt_registro] [datetime] NOT NULL,
CONSTRAINT [pk_DGA_log_error] PRIMARY KEY CLUSTERED
(
[id_cb_log_erro] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[DGA_log_error] WITH CHECK ADD FOREIGN KEY([id_erro])
REFERENCES [dbo].[dga_Erro] ([id_erro])
GO
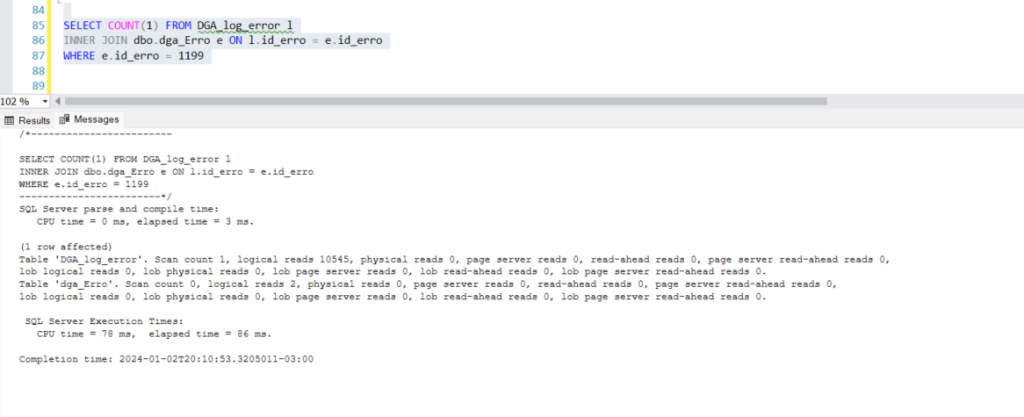
No print abaixo vemos que o próprio SQL sugere a criação de um índice e no plano faz a varredura na tabela dga_log_error no operador de clustered index scan e o seek na tabela dga_erro.

Ao executar a query vemos um alto volume de logical reads.
Então criei o índice para cobrir a FK.
CREATE INDEX id_01 ON dga_log_error(id_erro) WITH (DATA_COMPRESSION = PAGE)
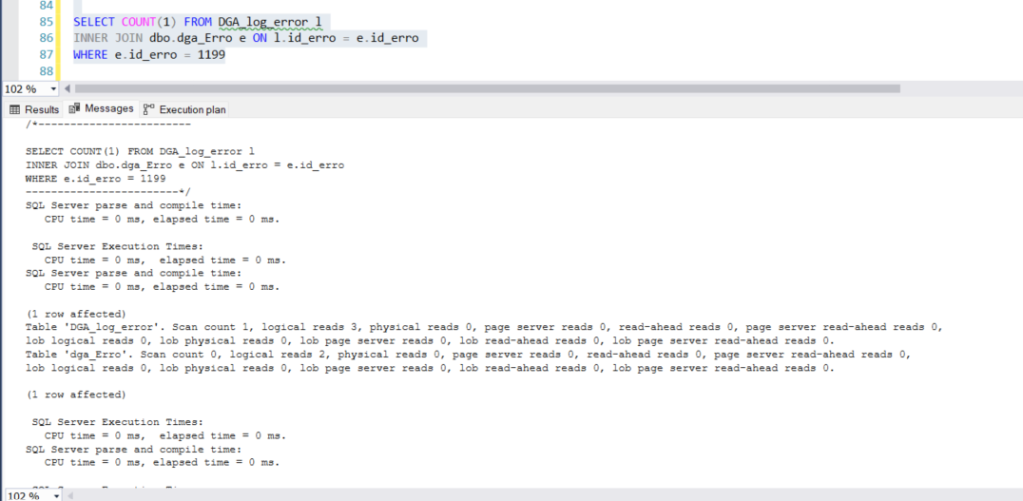
E executei novamente a query e vemos uma diferença gigante em quantidade de leitura, cpu e duração da execução.
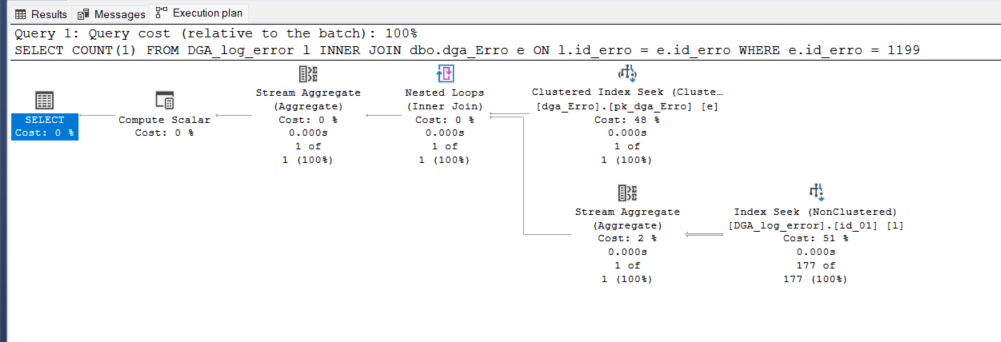
No plano de execução, se fez apenas o seek. (Não que o seek sempre seja o melhor, mas é na maioria das vezes).
Vou dropar o índice para executar a query que lista todas as FK’s sem índices.
DROP INDEX id_01 ON dga_log_error
Segue o script para identificar FK sem índices no SQL Server.
WITH v_NonIndexedFKColumns AS (
SELECT Object_Name(a.parent_object_id) AS Table_Name, b.NAME AS Column_Name
FROM
sys.foreign_key_columns a ,sys.all_columns b ,sys.objects c
WHERE
a.parent_column_id = b.column_id
AND a.parent_object_id = b.object_id
AND b.object_id = c.object_id
AND c.is_ms_shipped = 0
EXCEPT
SELECT
Object_name(a.Object_id)
,b.NAME
FROM
sys.index_columns a ,sys.all_columns b ,sys.objects c
WHERE
a.object_id = b.object_id
AND a.key_ordinal = 1
AND a.column_id = b.column_id
AND a.object_id = c.object_id
AND c.is_ms_shipped = 0
)
SELECT
v.Table_Name AS NonIndexedCol_Table_Name
,v.Column_Name AS NonIndexedCol_Column_Name
,fk.NAME AS Constraint_Name
,SCHEMA_NAME(fk.schema_id) AS Ref_Schema_Name
,object_name(fkc.referenced_object_id) AS Ref_Table_Name
,c2.NAME AS Ref_Column_Name
FROM
v_NonIndexedFKColumns v ,sys.all_columns c ,sys.all_columns c2 ,sys.foreign_key_columns fkc ,sys.foreign_keys fk
WHERE
v.Table_Name = Object_Name(fkc.parent_object_id)
AND v.Column_Name = c.NAME
AND fkc.parent_column_id = c.column_id
AND fkc.parent_object_id = c.object_id
AND fkc.referenced_column_id = c2.column_id
AND fkc.referenced_object_id = c2.object_id
AND fk.object_id = fkc.constraint_object_id
ORDER BY 1,2
Por isso é isso pessoal.
Abs

Mas qual a utilidade de ter chave substituta como chave primária na tabela DGA_log_error? Me parece que é uma chave primária inútil para uma tabela de log e que nunca será utilizada em junções ou pesquisas. Eu diria que a chave substituta é que causou o problema, nesse caso.
CurtirCurtir
Boa noite.
Obrigado pela resposta.
As tabelas são “fictícias”. Apenas aproveitei dados de cliente que já seriam excluídos, renomeando algumas colunas para fazer o post e exemplificar o impacto da falta de um índice em uma FK.
CurtirCurtir