Fala pessoal, tudo bem?
Hoje vou falar um pouco sobre as configurações padrão no Query Store e alguns cuidados que devem ser tomados quando alterados.
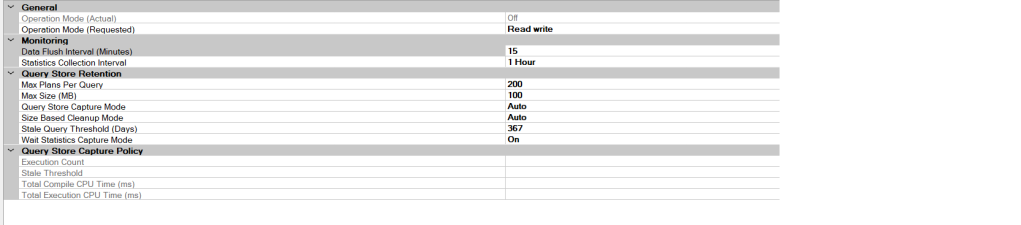
Por padrão, diferente do Azure Sql database e Azure SQL Managed Instance que são READ_WRITE, no SQL IAAS ou onpremise o Query Store é desabilitado por padrão.
Precisamos habilitar o query store no modo Read Write para que novas consultas, planos, estatísticas do tempo de execução e estatísticas de espera sejam capturados e planos forçados ainda sejam forçados.
Você pode obter todas as informações de configuração através da consulta:
SELECT * FROM [sys].[database_query_store_options];
DATA_FLUSH_INTERVAL (MINUTES):
É basicamente o tempo que as consultas e estatísticas de execução serão enviadas da memória para o disco e é recomendado manter os 15 minutos.
QUERY_CAPTURE_MODE :
O valor padrão para a opção QUERY_CAPTURE_MODE SQL Server 2016 e SQL Server 2017 é ALL e para versões superiores e para Azure Sql Database e Managed Instance, o valor padrão é AUTO.
Com essa config setada para AUTO, algumas consultas triviais ou pouco executada são descartadas. Caso não queira essa exclusão automática, configure para ALL.
Existe uma terceira opção, NONE, onde nenhuma nova consulta é capturada. As estatísticas de tempo de execução e de espera continuarão a ser capturadas para consultas que já estão no Query Store.
MAX_PLANS_PER_QUERY:
O valor padrão é 200.
Essa config deve ser realizada de acordo com sua carga de trabalho e quantidade de consultar utilizando planos distintos, o que não é muito bom pois pode causar o famoso cache bloated onde consultas geram diversos planos únicos inflando demais o plan cache e utilizando memória.
Para avaliar quantos planos distintos pode executar a consulta:
SELECT [query_hash], COUNT (DISTINCT [query_plan_hash])
FROM [sys].[dm_exec_query_stats]
GROUP BY [query_hash]
ORDER BY 2 DESC;
GO
O valor 200 parece um valor aceitável para essa config.
MAX Size (MB) | SIZE_BASED_CLEANUP_MODE | STALE_QUERY_THRESHOLD_DAYS
Essas configurações têm influência entre si e devem ser pensadas em conjunto.
MAX_STORAGE_SIZE_MB Especifica o limite do espaço de dados que o Query Store pode ocupar no banco de dados do cliente. Deve ser configurado de acordo com sua carga de trabalho.
SIZE_BASED_CLEANUP_MODE Especifica se a limpeza automática de dados ocorre quando o tamanho dos dados do Query Store se aproxima do limite. Recomando deixar em auto, para que o próprio SQL recicle os dados mais antigos.
STALE_QUERY_THRESHOLD_DAYS Política de limpeza baseada em tempo que controla o período de retenção de estatísticas de tempo de execução persistentes e consultas inativas. 30 dias é o padrão e você pode aumentar caso tenha um baixo volume de consultas sendo rastreadas.
Esseas valor varia de acordo com tipo e edição do SQL, no nosso exemplo, SQL 2019 Std etidion é 1000 MB.
Já falamos das configurações, mas gostaria de voltar em um especfícia.
Já sabeemos que precisamos configurar o Data Flush Interval (minutes) que é basicamente o tempo que as consultas e estatísticas de execução serão enviadas da memória para o disco. Decidi falar mais sobre isso pois peguei um ambiente que esse parâmetro estava configurado em 200 minutos, e eu me fazia algumas perguntas:
- “Será que ocorre um pico I/O ocorre quando o flush ocorrer?”
- Esse é o tempo máximo que ocorrerá essa sincronização com o disco, o SQL por si só tem mecanismos para descarregar de tempos em tempos.
- “Se o servidor for reiniciado, fazer sentido perder 200 minutos de dados coletados?”
- Para o cliente não fazia diferença pq a pessoa que habilitou não estava mais na empresa e ninguém usava essas informações.
- “Se vc procisar reiniciar o serviço do sql por qualquer motivo ou precisar fazer um failover programado, o SQL vai descartar os logs e partir para virar de nó?”
- Aí veio um ponto importante, pois até o SQL 2017 o comportamente padrão do SQL é ao iniciar o processo normal de stop/failover, aguardar até que tudo que está em memória seja descarregado em disco e .
Qual o impactado disso então? Suponha que você tem uma janela de manutenção de 3 a 5 minutos para fazer um faillover programado e você começa o processo e o SQL vai levar alguns minutos para descarregar as estatíticas do query store. Deu mais ou menos ruim!
A saída para essa situção é a utilização do trace flag 7745.
| 7745 | Força o Repositório de Consultas a não liberar dados para o disco no desligamento do banco de dados. Observação: em caso de desligamento, o uso desse sinalizador de rastreamento pode causar a perda dos dados do Repositório de Consultas que não foram liberados para o disco. Para um desligamento do SQL Server, o comando SHUTDOWN WITH NOWAIT pode ser usado em vez do sinalizador de rastreamento para forçar um desligamento imediato. Escopo: apenas global. |
E quando inicia o SQL Server, ele carrega alguns dados das tabelas internas do Query Store na memória. Isso em alguns casos pode demorar e tornar essa inicialização do banco lenta, normalmente gera alto tempo de espera do wait QDS_LOADDB. Como melhor prática, até o SQL 2017, é recomenado a utilização do trace flag 7752.
| 7752 | Habilita o carregamento assíncrono do Repositório de Consultas. Observação: Use este sinalizador de rastreamento se o SQL Server estiver apresentando um alto número de esperas QDS_LOADDB relacionadas à carga síncrona do Repositório de Consultas (comportamento padrão durante a recuperação do banco de dados). Observação: desde o SQL Server 2019 (15.x), esse comportamento é controlado pelo Mecanismo de Banco de Dados e o Sinalizador de Rastreamento 7752 não tem efeito. Escopo: apenas global. |
Então por hoje é isso pessoal.
Façam seus testes e quando forem habilitar o query store, fiquem atentos a qualquer desvio.
Abraços.
Referência:
http://www.sqlskills.com/blogs/erin/query-store-trace-flags/
